2022. 3. 15. 18:22ㆍSTUDY/머신러닝
분류모델 - SVM
출처 : https://hleecaster.com/ml-svm-concept/
출처 : https://en.wikipedia.org/wiki/Support-vector_machine
출처 : https://bskyvision.com/163
SVM(Support Vector Machine) 이란?
서포트 벡터 머신은 결정 경계(Decision Boundary : 분류를 위한 기준) 을 정의하는 모델이다.
아래의 예를보면
해당 데이터를 Average Numbere of Goals(1) 와 Average Time to catch Snitch(2) 속성 두가지로 분류할 수 있고
둘 사이의 Decision Boundary 는 아래 검은 직선이 되겠다.

하지만 두 속성을 나누는 선은 아래처럼 여러 형태로도 그려질 수 있을텐데
어떤 Decision Boundary 가 좋다고 할 수 있을까?

마진 ( Margin )
위 그림에서 가장 분류를 잘했다고 볼 수 있는것은 Graph F일것이다.
왜냐하면, 두 속성데이터로부터 멀리있으므로 오류를 범할 확률이 낮아
높은 확률로 잘 분류 할 수 있을거기 때문이다.

위 생각을 반영하여 그림을 설명하면
중간 검은색 실선 : Decision Boundary
중간 검은색 점선 : Decision Boundary 로 부터 제일 가까운 데이터*에대해 Decision Boundary 선에 평행하게 그은 선
* 해당 데이터를 Support Vector 라고 함.
|| 점섬 - 점선 || : 마진(Margin)**
** 해당 부분에 대해 많이 사람들간의 오류가 있는거같음 (나는 위키피디아 원문참고)
점선과 점선사이의 거리를 최대화 하는것이 정확도가 높을 것이므로
마진(Margin)을 최대화 하는 최적의 Decision Boundary 를 찾는게 최종 목표
선형 SVM 과 RBF 커널 SVM 의 비교
1. 선형 SVM
위 그림에서 2D 평면에 놓여져있는 데이터세트에 대해 직선으로 데이터를 구분하였다.
직선(선형)으로 데이터를 간단하게 구분할 수 있는 SVM 방식을 선형 SVM 이라고 한다.
하지만, 만약 아래처럼 데이터형태가 단순한 직선으로 구분할 수 없는 경우 어떻게 해야할까?

위처럼 기본적인 SVM만으로 데이터를 제대로 분류할 수없는 상황이 상당히 많을텐데
해당 부분을 해결하기 위한 방법이 RBF 커널 SVM이다.
2. RBF(Radial basis function) 커널 SVM
위 그림처럼 2D 평면상에 놓인 데이터를 분리 할 수 있는 방법은 뭘까?
우리가 볼펜을 가지고 긋는다면, 그냥 원을 그려주면 될거같다.
하지만 컴퓨터가 데이터를 처리하는 방식에서 해당 아이디어를 적용하려면 어떻게해야할까?
데이터를 고차원 feature space 로 맵핑해주는 것이다.
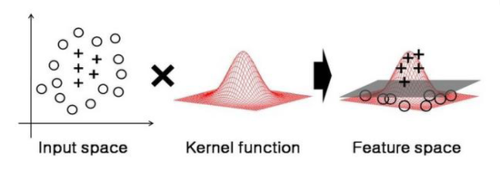
데이터를 고차원 공간에 맵핑해주고 나면, 원래 차원에서는 보이지않던 분류 방법이 보이게 된다.
고차원 공간으로 맵핑된 데이터를 분류하고 다시 원래차원으로 돌려준다면 올바른 분류가 가능하게 될 것이다.

커널함수에는 여러가지 종류가 있다. (Polynomial kernel, sigmoid kernel, gaussian RBF kernel 등...)
그중 가장 성능이 좋고 자주 사용되는것이 Gaussian RBF kernel이다.
SVM 의 매개변수
RBF Kernel에 대한 조금 자세한 설명을 들어가기전에 알아보고 갈것이 있다.
그것은 바로 SVM 이 사용하는 매개변수는 무엇일까?
1. 선형 SVM
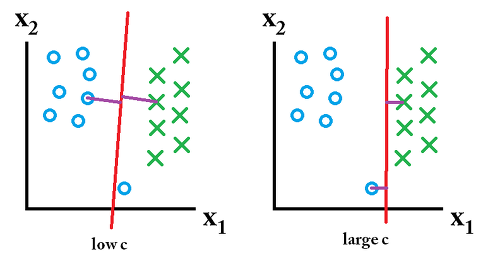
선형 SVM을 수행하면, 이상치 데이터는 항상 존재하기 마련이다.
그래서 분류 수행시, 이상치를 어느정도 인정해주는지 파라미터값으로 지정해주어야 한다.
해당값을 C(cost)라고 하며
1) Cost값이 작을 경우 : 손실이 작다 --> Margin 크다. --> 이상치를 어느정도 허용한다. --> 심할경우 underfitting
2) Cost값이 클 경우 : 손실이 크다 --> Margin 작다 --> 이상치를 잘 허용하지 않는다. --> 심할경우 overfitting
참고로, Cost값이 작을경우 Soft margin SVM, Cost값이 클 경우 Hard margin SVM 이라 한다.
2. RBF 커널 SVM
선형 SVM은 파라미터로 C(cost)를 가지고 있다.
RBF 커널 SVM의 경우에는 C(cost)를 가짐과 동시에 gamma 라는 추가적인 파라미터를 가지고있다.
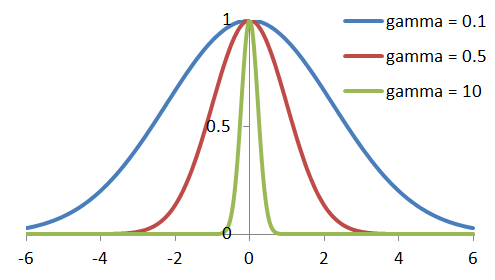
gamma는 데이터 샘플이 영향력을 행사하는 거리의 정도를 의미한다.
gamma는 가우시안 분포의 표준편차와 관련이 있는데
1) gamma 작다 --> 표준편차 크다 --> 영향력행사 거리가 길다. --> 심할경우 underfitting
2) gamma 크다 --> 표준편차 작다 --> 영향력행사 거리가 짧다. --> 심할경우 overfitting
파라미터 정리 설명
아래 그림을 보면서 마지막 정리
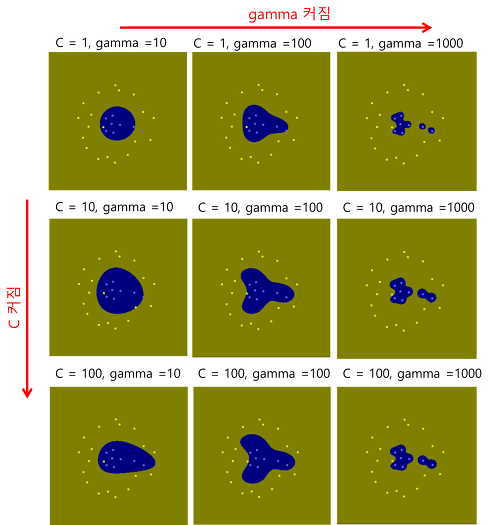
1열(gamma고정)을 보자.
C값이 커지면 커질수록 이상치의 허용을 줄이기 위해 찌그러진 형태로 변하는 것을 볼 수 있다.
1행(C 고정)을 보자
gamma값이 커지면 커질수록, 영향력을 행사하는 길이가 짧아져 영역범위가 줄어드는것을 볼 수있다.
기억
C & Gamma 값 증가하면 증가할수록 Overfitting 할 수 있다.
- C 증가인데 Overfitting? --> 이상치의 허용을 줄이는 구나
- Gamma 증가인데 Overfitting? --> 영역범위가 점점 줄어드는 구나
사용법
파이썬 scikit-learn 라이버르리에서 SVM을 제공해준다. (https://scikit-learn.org/stable/modules/svm.html#svm)
scikit-learn 에서 설명하는 SVM
Support Vector Machine는 분류/회귀/이상탐지를 가능케하는 지도학습 알고리즘 중 하나이다.
이점
- 고차원공간의 데이터에도 효율적이다.
- 샘플수보다 차원수가 많을때도 효과적이다.
- decision boundary를 결정하는데에, 데이터세트의 일부분인 Support vector만 사용하면 되므로, 비용효율적이다.
- 여러가지 kernel function을 적용할 수 있고, custom도 가능하다.
단점
- 만약 feature의 수가 샘플의수보다 훨씬많을경우 kernel function을 사용하여 과적합을 피해야하고, 정규화 필수다.
- SVMs do not directly provide probability estimates, these are calculated using an expensive five-fold cross-validation (see Scores and probabilities, below). --> 교차검증을 여러번해야 확률적 추정값이 도출된다? 이말인가?
scikit-learn에서 제공해주는 SVM 클래스는, 데이터타입 두가지(Dense,sparse) 전부 입력으로 받을 수 있다.
하지만 sparse data의 경우 특정데이터에 fit 될 우려가있다. 좋은 성능을 내기위해서는
C-ordered numpy.ndarray 또는 scipy.sparse.csr_matrix(sparse) with dtype=float64를 사용해야한다.
제공해주는 클래스 세가지
1. LinearSVC
선형 분리만 가능한 간단한 SVC (커널함수 지원X)
속도가 가장 빠르다.
2. SVC
기본이되는 SVC로 여러 커널함수 지원하여, 고차원맵핑가능
지원해주는 커널함수는 아래와 같다.

예) RBF 커널을 사용할 경우
# RBF 커널사용
svm.SVC(C=C, gamma=gamma)
svm.NuSVC(gamma='auto')
'STUDY > 머신러닝' 카테고리의 다른 글
| [지도학습] 회귀모델 - 추가내용 ( 비선형회귀 & 학습과정 ) (0) | 2022.03.14 |
|---|---|
| [지도학습] 회귀모델 - 로지스틱 회귀 (0) | 2022.03.14 |
| [지도학습] 회귀모델 - 선형 회귀 (0) | 2022.03.14 |
| [지도학습] 분류모델 - K Nearest Neighbors (0) | 2022.03.11 |