Transformer 1. 전통적인 RNN기반 인코더-디코더 모델
2022. 3. 29. 09:46ㆍSTUDY/Model
Seq2Seq Model
RNN 기반 인코더-디코더 모델

전통적인 RNN기반 인코더-디코더 모델은 위와 같다.
- 순차적으로 들어오는 입력들에 대해서 전부 Hidden state를 계산하여 다음 time-step으로 넘김
- 인코더에서는 입력된 문장들의 정보를 압축하여 Context vector 얻음
- 디코더에서는 Context vector로 부터 번역된 문장을 도출
특징은 다음과 같다.
- Context vector가 고정된 크기다. 따라서 긴 입력문장의 경우 모든정보 압축이 힘들다.
- 해당 문제를 보완하기 위해 등장한 매커니즘이 "Attention" (나중에 나옴)
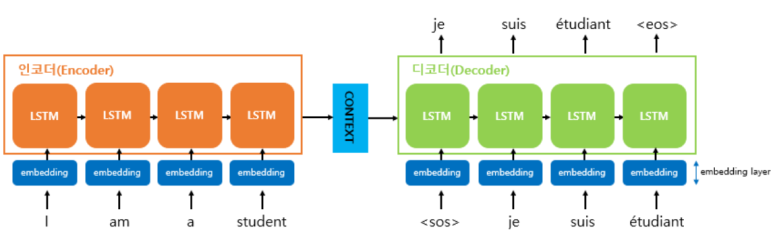
전체 구조 및 과정은 위와 같다.
- 입력 문장 토큰화 수행
- 토큰들은 Word embedding 통과
- 각 RNN셀의 입력으로 들어감
- 인코더 마지막 셀의 Hidden state가 Context vector이며
디코더셀의 첫번째 hidden state로 사용

디코더 부분의 과정은 위와 같다.
- 각 time-stemp의 RNN의 출력벡터가 나옴
- FC layer(Dense layer) 통과
- Softmax 함수를 통해 다음단어에 대한 각각의 확률값 반환
- 단어별 확률값을 기반으로 출력단어 결정
NLP 에서 Seq2Seq 과정
출처 : https://wikidocs.net/24996
1. 전처리과정
- 데이터가져오기
- 데이터를 기반으로 문자집합 구축
- 문자집합에서 각 문자에 대해 인덱스부여
- 각 번역문장마다 <sos> <eos> 부여
2. 모든 문장(단어들)에 대해 인덱스부여
- 문자별로 지정된 인덱스로 데이터에 전부 인덱스부여 (딕셔너리 사용)
- 디코더의 출력문장(예측문장)과 비교하기위한 실제값에는 <sos>가 필요없으므로
<sos>빼준 리스트 추가적으로얻음
3. 패딩
- 문장들을 묶어서 행렬로 바라보고 연산수행하기위해 문장길이맞춰줌
4. 모델 설계 및 학습
- 학습은 Teacher forcing을 통해 학습
출처
https://www.youtube.com/watch?v=mxGCEWOxfe8&list=WL&index=2
'STUDY > Model' 카테고리의 다른 글
| Transformer 3. Attention is all you need (0) | 2022.03.29 |
|---|---|
| Transformer 2. Attention 매커니즘이 추가된 인코더-디코더 (0) | 2022.03.29 |